Here you will get introduction to data mining.
We are back again in front of you with another successive Machine Learning blogpost. So far we have covered many interrelated topics pertaining to ML and today we think should start with another such interdisciplinary subject Data Mining or more appropriately Knowledge Mining. We must tell you that Data Mining does not only play a vital role in the field of ML but also sets its foot in the ever growing technological domain. Data is considered as the backbone of any industry and so is the Data Mining. Availability of right kind of data at the right moment acts like magic for business and can boost it by providing crucial information and demographics about the consumer.
What is Data Mining?
Let’s make this simpler for you to understand the terminology even better. Think of it in this way, when gold is mined from rocks and sands it is referred to as gold mining not sand or rock mining, right? Exactly in the same way when we dig deeper we would realise that instead of calling it data mining, the process should be more accurately termed as “knowledge mining from data”, which is lengthy enough to be used in day to day lives. Therefore the term Data Mining prevails widely.
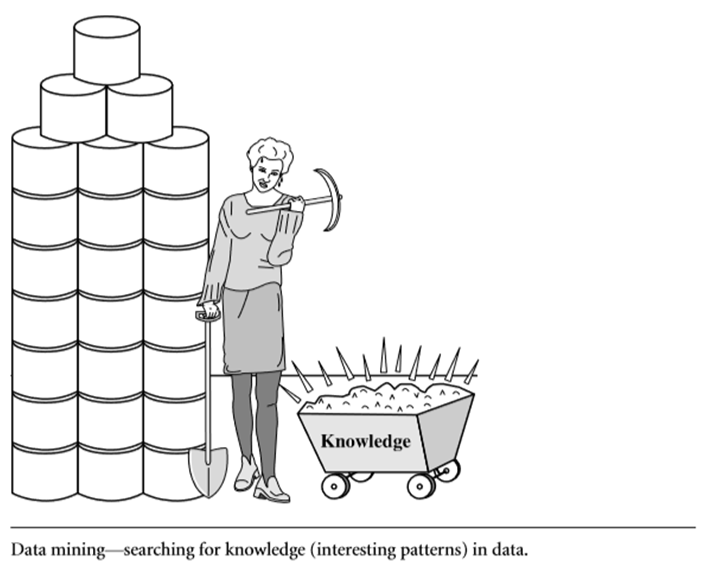
Synonymously several other terms are being used in the industry alternative to data mining such as, knowledge extraction, data archaeology, data/pattern analysis and data dredging.
A major portion of people out there use the terms data mining and knowledge discovery from data, or KDD interchangeably, while some others view data mining as just an essential step in the process of knowledge discovery.
Now, when we’ve talked about the knowledge discovery from data (KDD), let us have a quick sneek peek to get an overview of what KDD is? And more precisely what steps are involved in KDD.
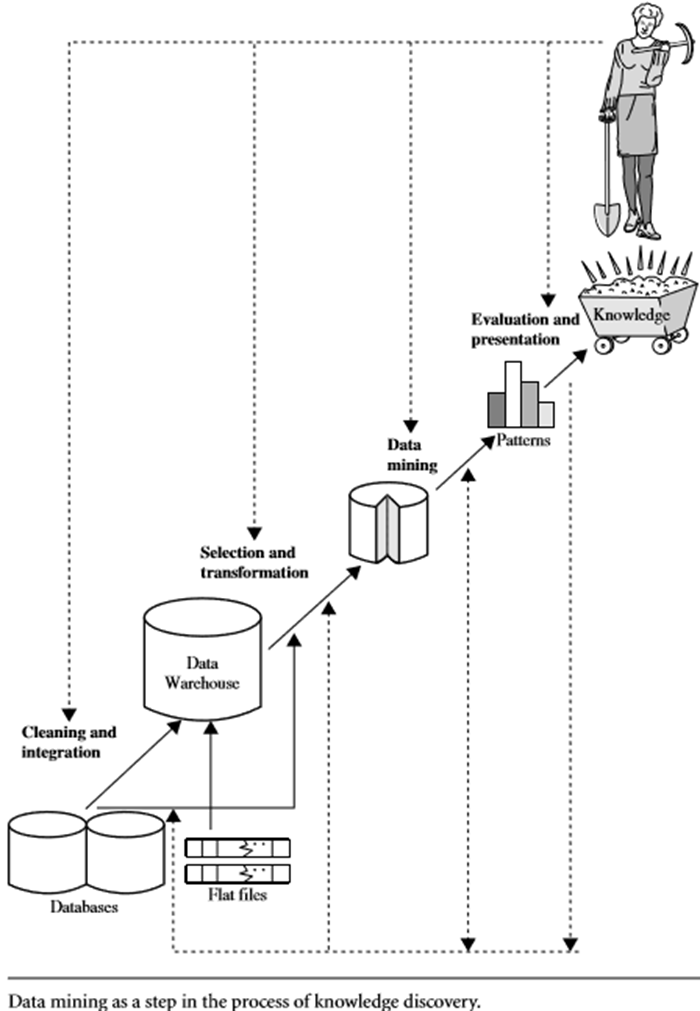
Steps in KDD
- Data Cleaning: To eliminate noise, inconsistency and redundancies from the data.
- Data integration: Multiple sources to provide data are possibly combined in this step.
- Data Selection: Data that are important to the analysis are only retrieved from the database
- Data transformation : The data are converted into the forms suitable for mining by applying aggregation operations.
- Data mining: One of the most crucial step where intelligent and predetermined methods are used to get patterns in the data.
- Pattern evaluation: To explore the interesting and valuable patterns representing knowledge among several thousands of similar patterns.
- Knowledge presentation: Knowledge representation and visualization techniques are applied to present the extracted knowledge to the users.
Summary of the Steps Involved:
Steps 1, 2, 3 and 4 are the distinct types of data pre-processing, result of which are the used for the mining purpose. The data mining step may interact with the user or a knowledge base. The relevant and important patterns are made available to the users and can also be saved in the form of new knowledge in the knowledge base.
Rest of the steps (step 5, 6, 7) also play crucial role in the entire mining process. Data mining is primarily the technique to discover interesting patterns and knowledge from huge data. The data sources consist of databases, data warehouses, the web, other information repositories, or data that are streamed into the system dynamically.
Why is Data Mining required?
In day to day lives we very often come across data and data mining techniques provide mechanisms and tools to analyse those data. Data mining is also crucial to extract knowledge from the available data. Moreover data mining can be interpreted as a result of the continuous evolution in the information technology.
We already are aware about the fact that we are living in the information age and tons (terabytes and petabytes) of data are flowing into our networks facilitating our business requirements and fulfilling our data needs. In the past few decades we have seen a tremendous increment in the volume of data present and the sole reason for this is the computerization and introduction of the advance and capable tools for data collection and discovery of knowledge from the available data.
How data are generated?
We can understand this by taking example of any one of business or stores like Mc Donald’s, KFC, or Wal-Mart which produces gigantic data like their sales record, transactions, sales promotions, company profiles etc. Such companies/stores handle millions of transactions per week at several hundreds of branches across the globe.
Apart from big stores and companies, engineering and scientific practices are too capable of generating petabytes of data in continuity. Processes like remote sensing and scientific experiments are primarily responsible for this. Moreover the very obvious source of generating humongous data is the telecommunication network which produces large datasets on the daily basis.
Also the web searches and different social platforms, Web communities and blogs generate data that are endless. This presence of huge amount of data from various sources and desperate need of the tools to uncover useful knowledge from these data inspire the need to explore such domains and is giving rise to data mining principles and techniques.
Additionally data mining can be viewed as a result of the evolution of the information technology over ages. The different functionalities which resulted due to the evolution of database and data management industry are depicted below with the help of an image.
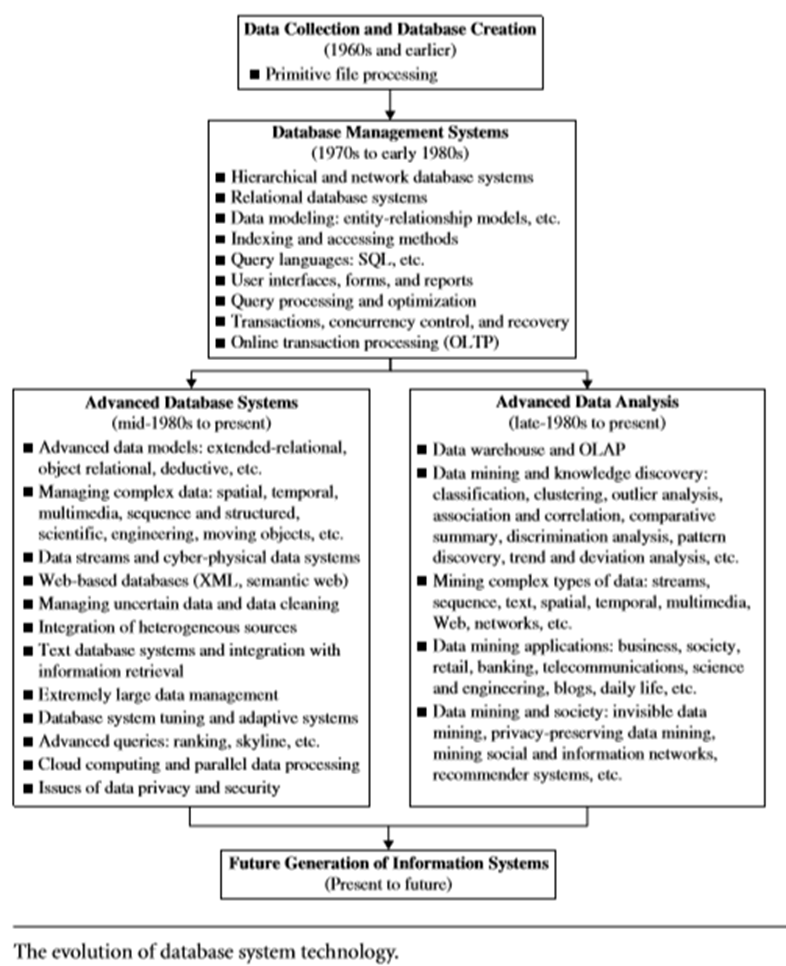
We hope things in the mind are pretty much clear from the image description above. If still there exists some ambiguity or doubt please let us know in the comment section, we will be happy to help.
Moving on we will now study what are Database and Data warehouse relative to the concept of data mining and how are they different from each other.
Databases and Data Warehouses
People often treat these two terms as same or interchangeably. We must tell you that two terms are not synonymous to each other. Both stand for a distinct meaning and must be treated accordingly.
What is Database?
In a layman’s language we can say that a database is a memory space which we can use to store our data.
Moreover we can understand database as a repository which is used by businesses, in science and engineering, research, etc. to store huge amount of data for day to day or future use. A database is known to store the current data like transactions occurring at thousands of Wal-Mart outlets around the world, number of users visiting a blog or even demographics of the persons applying for a passport.
The type of the data being able to be stored in the databases varies widely and nearly data belonging to any of the domain from buyer’s information in the local store to the results derived from the aerospace research. It is said and believed that the data that is stored within the database is dynamic and is meant to be used for day to day transactions.
We think we have discussed sufficient on databases now let’s quickly jump to our next topic which is Data Warehouse.
What is Data Warehouse?
The phrase “A data warehouse refers to a database that is maintained separately from an organization’s operational databases” says it all. However according to a great data scientist, a data warehouse is a subject-oriented, integrated, time variant and non-volatile collection of data in support of management’s decision making process. Let’s make this easier for you to grasp.
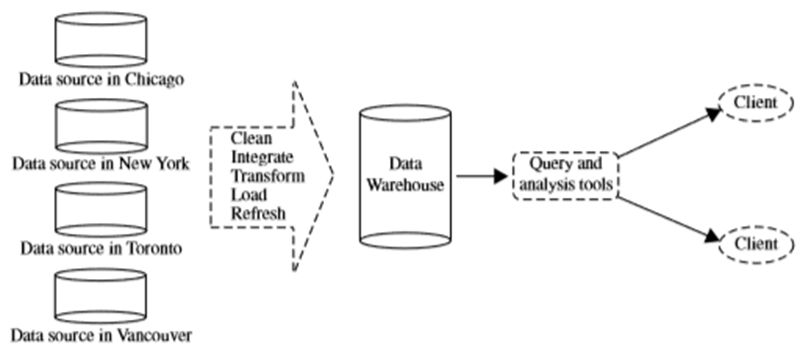
Suppose there is a big multinational company (say XYZ) which has its branches spread all across the globe. Each of the branches has their own set of databases. Now the chairperson of the company has asked to provide a summary of company’s sales per item type per branch for some specified time. This is relatively tough to accumulate the data that are physically spread at different sited all over the world.
If XYZ had a data warehouse it would be quite easy to accomplish the task defined above. A data warehouse is a repository of knowledge accumulated from several sources, stored under a unified schema, and most probably residing at a single physical location.
Structure of a typical data warehouse for XYZ company is given below for the users reference.
Types of Data Warehouse
- Enterprise Data Warehouse
- Operational Data Store/Virtual Warehouse
- Data Mart
We will study about different types of data warehouses in the future posts if required.
Difference between Database and Data Warehouse
| Database System | Data Warehouse |
| Stores current data | Stores historical data |
| Data is dynamic | Data is largely static |
| Used for daily transaction | Used for analysis of data |
| Application-oriented | Subject-oriented |
Why should we have a separate data warehouse?
Operational database store huge amount of data, you may wonder “why can’t we perform online analytical processing directly on such databases despite of providing additional time and resources to make a separate data warehouse?” A major reason for such separation is to help promote the high performance of both systems.
Multidimensional Data Model
Data warehouses and Online Analytical Processing (OLAP) tools are based on a multidimensional data model. This model views data in the form of cube (a three dimensional structure).
What is data cube?
A data cube is a means which permits data to be modelled and viewed in multiple dimensions. It is defined by dimensions and facts. A typical structure of a data cube is given below for reference:
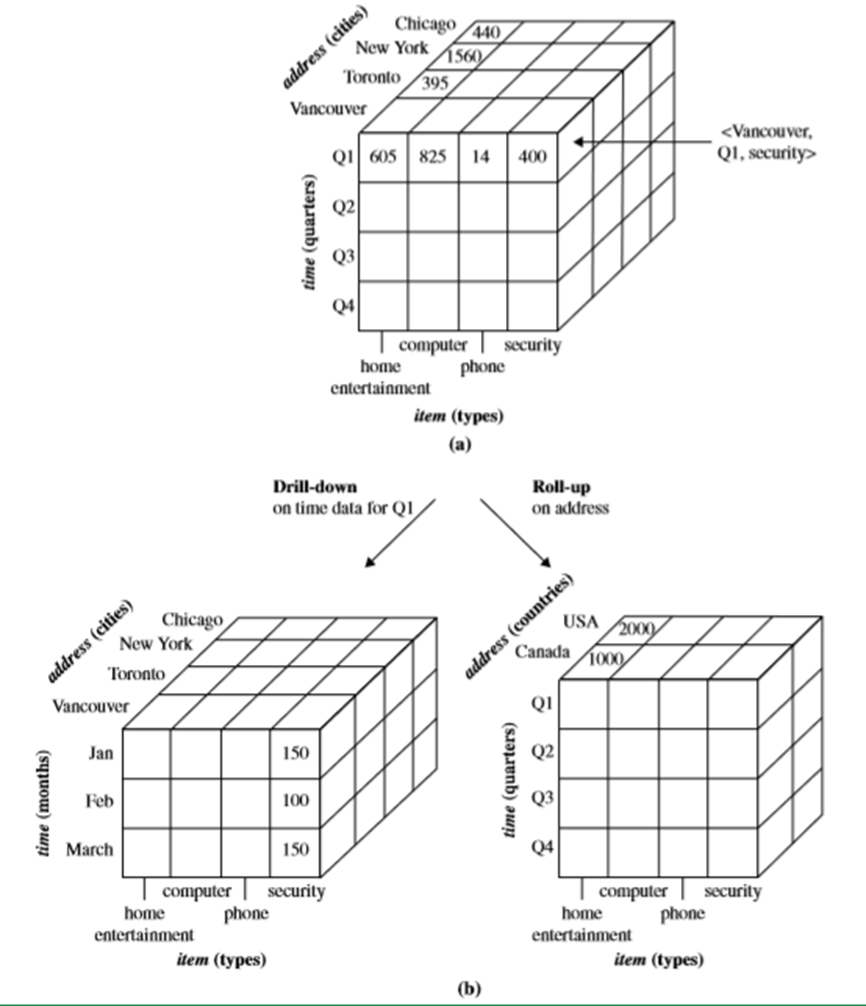
It is clearly visible from the snap above that how data can be represented in multiple dimensions instead of only two dimensions that most people think.
The dimensions in general are entities or variables with respect to which an organization (say XYZ) wants to keep records. Let us again take example of XYZ company that we have talked about. The XYZ company may create a data warehouse pertaining to sales to keep records of the branch’s sales with respect to the dimensions like time, item, branch, demand, etc. These entities or dimensions help company keep record of things like monthly sales and the branches at which the items were sold. Also with every dimension there is a table associated to keep such tracks and is popularly known as Dimension Table. Further it is proved that cube is not only 3D but can be n-dimensional depending upon the requirement. The famous representations used to represent the multidimensional models are Star, Snowflakes and Fact constellations. We are not going to cover the models in this post and is for the overview purpose only.
Different tools and utilities are being used by the data warehousing systems to make their data denser and to refresh them periodically. The functions that are being carried out by such tools include:
Data Extraction: The process of accumulation of data from various heterogeneous sources
Data Cleaning: Involves detection and rectification of the errors whenever possible
Data Transformation: as clear from the term itself, transformation of the data is carried out. That is data is transformed from its conventional form into the form suitable for data warehouse.
Load: A series of functions are performed at this very step like sorting, summarization, consolidation, computation of views, checking integrity and building indices and partitions of the dataset.
Refresh: This process is basically responsible for propagating the updates from data sources to the warehouse.
Besides these tools the data warehouse system also provides a set of tools beneficial for the management of the data warehouses.
Image Sources: All the images presented in this blog are taken from book Data Mining Concepts and Techniques by Jiwaei Han, Micheline Kamber & Jian Pei and belong to their respective owners.
We think this is sufficient piece of knowledge for today. We wish our readers are not facing any difficulties while learning. Our only motto is to facilitate our readers to get a good grasp over the content being exposed to them. If there persist any issue regarding data mining or if there is something you can’t really understand, please let us know via comments below, we are there to resolve the doubts.
The post Introduction to Data Mining appeared first on The Crazy Programmer.
from The Crazy Programmer https://www.thecrazyprogrammer.com/2018/02/introduction-to-data-mining.html
Comments
Post a Comment