Data structures are a very important programming concept. They provide us with a means to store, organize and retrieve data in an efficient manner. The data structures are used to make working with our data, easier. There are many data structures which help us with this.
Types of Data Structures
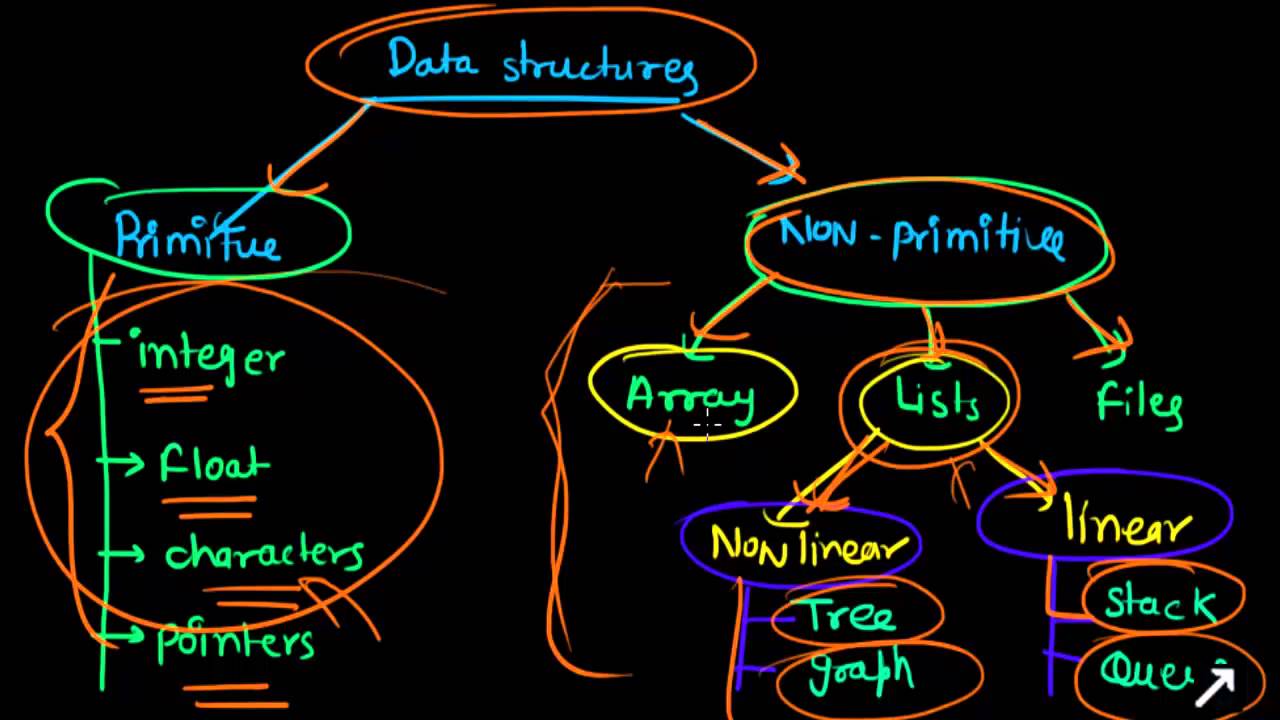
Primitive Data Structures
These are the structures which are supported at the machine level, they can be used to make non-primitive data structures. These are integral and are pure in form. They have predefined behavior and specifications.
Examples: Integer, float, character, pointers.
The pointers, however don’t hold a data value, instead, they hold memory addresses of the data values. These are also called the reference data types.
Non-primitive Data Structures
The non-primitive data structures cannot be performed without the primitive data structures. Although, they too are provided by the system itself yet they are derived data structures and cannot be formed without using the primitive data structures.
The Non-primitive data structures are further divided into the following categories:
1. Arrays
Arrays are a homogeneous and contiguous collection of same data types. They have a static memory allocation technique, which means, if memory space is allocated for once, it cannot be changed during runtime. The arrays are used to implement vectors, matrices and also other data structures. If we do not know the memory to be allocated in advance then array can lead to wastage of memory. Also, insertions and deletions are complex in arrays since elements are stored in consecutive memory allocations.
2. Files
A file is a collection of records. The file data structure is primarily used for managing large amounts of data which is not in the primary storage of the system. The files help us to process, manage, access and retrieve or basically work with such data, easily.
3. Lists
The lists support dynamic memory allocation. The memory space allocated, can be changed at run time also. The lists are of two types:
a) Linear Lists
The linear lists are those which have the elements stored in a sequential order. The insertions and deletions are easier in the lists. They are divided into two types:
- Stacks: The stack follows a “LIFO” technique for storing and retrieving elements. The element which is stored at the end will be the first one to be retrieved from the stack. The stack has the following primary functions:
- Push(): To insert an element in the stack.
- Pop(): To remove an element from the stack.
- Queues: The queues follow “FIFO” mechanism for storing and retrieving elements. The elements which are stored first into the queue will only be the first elements to be removed out from the queue. The “ENQUEUE” operation is used to insert an element into the queue whereas the “DEQUEUE” operation is used to remove an element from the queue.
b) Non Linear Lists
The non linear lists do not have elements stored in a certain manner. These are:
- Graphs: The Graph data structure is used to represent a network. It comprises of vertices and edges (to connect the vertices). The graphs are very useful when it comes to study a network.
- Trees: Tree data structure comprises of nodes connected in a particular arrangement and they (particularly binary trees) make search operations on the data items easy. The tree data structures consists of a root node which is further divided into various child nodes and so on. The number of levels of the tree is also called height of the tree.
Data structures give us a means to work with the data. Since, we already have lots of problems to deal with, it completely depends on the requirement of our problem which data structure to select. The right selection of an appropriate data structure for solving a particular problem can prove very beneficial and also help reduce the complexity of the program.
The post Types of Data Structures appeared first on The Crazy Programmer.
from The Crazy Programmer https://www.thecrazyprogrammer.com/2018/10/types-of-data-structures.html
Comments
Post a Comment